My Text in Your Handwriting
It seems like forever since I last posted about my research. This paper actually took three years and four days, from the first day I worked on it through to the day it was accepted! Obviously I worked on other stuff during that period, but its still a hell of a long time for one paper, even if the results are awesome (Well, I think so!). Its also long: 15 pages (double column!), followed by 2 pages of references then 11 pages of appendices (a total of 28 pages), not to mention the almost 9 minutes of supplementary video. I almost feel sorry for the reviewers, but then they kept asking for it to be longer...
Put simply, we present a method that allows us to replicate the handwriting of anyone for whom we have a sample. Any scan will do - nothing special is required at capture time. So we can take a sample of Arthur Conan Doyle's handwriting and write anything we want in it:
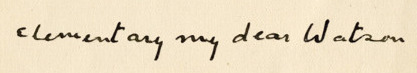
Sherlock Holmes does not say that in any of the books Arthur Conan Doyle wrote - it was actually introduced by a 1929 film (Or possibly a stage play in 1899. Or possibly in a totally different series of books by P. G. Wodehouse in 1915. Its fuzzy.). The above is a historical impossibility.
Here is the main video:
My favourite bit is the replacement of text in a film. I had a lot of fun setting up a green screen in my bedroom, with proper lighting, and then building a virtual set (camera mapping of a HDR photo) to composite it into. There was a wide shot with a corpse in the original, but that got cut for some reason... The mini-music video is also particularly fun - just don't ask how many takes it took to get it in time with the music! There is also an interface video.
You can download the paper here: My Text in Your Handwriting (Warning: That includes all of the appendices, so you may want to print just the first 18 pages.), and it also has a project web page over at UCL. Edit: Its now up on the ACM website
Code is now published, and can all be found at https://github.com/thaines/helit/tree/master/handwriting. In addition, there are three data sets you may want to download:
The Project Gutenberg corpus, used to get the statistics of English, and provide sentences for authors to write out.
The random forest models learnt from the data, to save you learning them yourself if you have are going to be running the code.
Finally, the handwriting samples used for the user studies. Please don't download this unless you really intend to use it, as its rather large!
In addition, you can download the SIGGRAPH slides.
Its not a paper for which I can give a one line technical summary - its a systems paper rather than an algorithm paper (not that we set out planning to make a systems paper!). Technologies used include dynamic programming, Kalman smoothing, graph cuts, random forests, mean shift, transfer learning and a whole bunch of image processing operations. One of my favourite tricks is where I smooth text in a signed distance function representation to ensure that thin lines don't get destroyed, but there is so, so much in there. You will have to read the paper! The key point is it really does work. We tested it on real humans (well, humans found at a university, which are a reasonable approximation) and they were unable to tell the difference between real and fake, even when we gave them examples of the authors real handwriting (I get it right most of time, but not always!).
So why did we do it? (beyond the usual 'because we can', of course) There were some jokes about using it to rob banks - we are poor academics after all. But to be serious some disabilities take away a persons ability to write, a stroke for instance, and in such cases the ability to replicate your own handwriting (training the model using pre-disability examples), may mean a lot. There is also all the trivial/potentially profitable stuff. The most prominent example is that gift/flower/card companies always include this horrible printed message. Our system would allow much greater personalisation, either with your own handwriting or with the handwriting of a celebrity (who would presumably get a royalty! The world just keeps getting stranger...). It also allows us to rewrite history, as demonstrated above, so I'm sure that the Ministry of Truth will be very interested;-)
Now out of date (see above): Code will be published, but is not online yet (Well, the mean shift module is.). This is the largest, most complex system I have ever created, and its going to take months to get it all cleaned up and online. I will be presenting this paper at SIGGRAPH 2016, so am aiming to get it all done by then. We will also be releasing our dataset - that will happen much quicker, but there is little value until we have also released code to load the included files.
Regarding presenting at SIGGRAPH, that did not happen. Broke my ankle badly two weeks before, playing football (Which I don't even like!), and am still incapable of moving more than 50-100m without somewhere to rest as I write this, on the day I was meant to present. After three and a half years it's hard to think of a bigger possible let down:-(
Edit (20th August 2016): So I got a consolation prize of sorts after missing SIGGRAPH - lots of media attention. Then lots of emails, which is clearly a punishment. It took sooooo long to answer them all. Anyway, here is a list of articles about this paper:
BBC: The original article that spawned the rest, and one of the few that wasn't lazy journalism, as Rory actually came along and spent the time to talk to me, with a camera man. Timing was not the best, as the interview was the morning of the last day of 3Dami, and required preparation as Rory sent me his handwriting sample the evening before. All whilst hoping around on crutches. That was an insane day.
UCL: Obviously UCL did their own press-release thing. Very quote heavy, but accurate at least, as I got to proof read it.
A German TV show made the effort to travel to the UK and film me for a piece. Was good fun, but Google translate gives the title as "Falsifying manuscripts - crimes with artificial intelligence", so I suspect they may have portrayed me as an evil mastermind. I'm OK with that.
Digital Trends: They actually put in the effort to send me a few questions via email. It amuses me that they think my algorithm is creepy!
I got emailed some questions by the Haberturk Gazette. Can't find actual article however, as I don't know Turkish!
Reddit: So someone started a reddit discussion about it. The take home message seems to be that people want a homework machine, and this is a critical component. Someone needs to submit a grant:-P Also a concern about its use for spam mailing, which I never even considered. Worryingly, that actually seems like a serious possibility, and not something I want to be associated with. Crap.
CG Channel: This actually came before the BBC article, but given its nature nobody noticed it. Just a list of cool SIGGRAPH videos, with my handwriting paper under 'Just plain fun'. Much happier with that than 'potential spam enabler'!
Below are all articles where a journalist has read the BBC article/UCL press release and basically copied it. This is not to say they are all the same - some of them have put effort into the presentation, and its interesting to see all of the different twists/opinions they have added:
Treehugger - The use of the word 'perfectly' in the headline amuses me. If it really was perfect we would have a serious fraud problem - sometimes you actually want to fall a little short!
Gizmondo: Talk about a lazy title - those are Rory's words. To answer the question at the end about the authors own handwriting - it totally could. Your handwriting isn't actually that bad. I should know...
Engadget: OK article, author was clearly paying attention as it has a lot of details and I didn't spot any mistakes.
BT: Close examination by a magnifying glass. A normal one, that any kid can use to brutally murder ants. Not a microscope.
India TV news: Its a website. Not a TV. With a click bait headline. I am hopeful that there is going to be a point in history where the hatred of this click bait crap leads to certain words, such as wow, being banned entirely from headlines by editors.
Golem: A German one that a friend sent me. Don't speak German, though its apparently in the 'Algorithmus' section, which I think might be a gorgeous word.
The Malta Independent Online: Just a stub.
dna: An Indian stub.
Phys Org: Longish stub
I4U News: Stub.
Opp Trends: Short and wrong. They clearly tried to read the paper, and got confused somewhere, or possibly everywhere.
Cantech Letter: A stub that is apparently bought to me by eye carrot. I don't know what an eye carrot is, but it sounds painful, or at least inconvenient.
The Technews: Stub. Where do all of these stock photographs of pens on paper come from? There are just so many of them - is the market for pens on paper images really that large?
The Hindu Business Line: Another stub. Disappointed with so many foreign news websites being in English - I want all the languages!
There are more, but in the words of Miss sweetie poo, I'm bored.
Put simply, we present a method that allows us to replicate the handwriting of anyone for whom we have a sample. Any scan will do - nothing special is required at capture time. So we can take a sample of Arthur Conan Doyle's handwriting and write anything we want in it:
Sherlock Holmes does not say that in any of the books Arthur Conan Doyle wrote - it was actually introduced by a 1929 film (Or possibly a stage play in 1899. Or possibly in a totally different series of books by P. G. Wodehouse in 1915. Its fuzzy.). The above is a historical impossibility.
Here is the main video:
My favourite bit is the replacement of text in a film. I had a lot of fun setting up a green screen in my bedroom, with proper lighting, and then building a virtual set (camera mapping of a HDR photo) to composite it into. There was a wide shot with a corpse in the original, but that got cut for some reason... The mini-music video is also particularly fun - just don't ask how many takes it took to get it in time with the music! There is also an interface video.
You can download the paper here: My Text in Your Handwriting (Warning: That includes all of the appendices, so you may want to print just the first 18 pages.), and it also has a project web page over at UCL. Edit: Its now up on the ACM website
Code is now published, and can all be found at https://github.com/thaines/helit/tree/master/handwriting. In addition, there are three data sets you may want to download:
The Project Gutenberg corpus, used to get the statistics of English, and provide sentences for authors to write out.
The random forest models learnt from the data, to save you learning them yourself if you have are going to be running the code.
Finally, the handwriting samples used for the user studies. Please don't download this unless you really intend to use it, as its rather large!
In addition, you can download the SIGGRAPH slides.
Its not a paper for which I can give a one line technical summary - its a systems paper rather than an algorithm paper (not that we set out planning to make a systems paper!). Technologies used include dynamic programming, Kalman smoothing, graph cuts, random forests, mean shift, transfer learning and a whole bunch of image processing operations. One of my favourite tricks is where I smooth text in a signed distance function representation to ensure that thin lines don't get destroyed, but there is so, so much in there. You will have to read the paper! The key point is it really does work. We tested it on real humans (well, humans found at a university, which are a reasonable approximation) and they were unable to tell the difference between real and fake, even when we gave them examples of the authors real handwriting (I get it right most of time, but not always!).
So why did we do it? (beyond the usual 'because we can', of course) There were some jokes about using it to rob banks - we are poor academics after all. But to be serious some disabilities take away a persons ability to write, a stroke for instance, and in such cases the ability to replicate your own handwriting (training the model using pre-disability examples), may mean a lot. There is also all the trivial/potentially profitable stuff. The most prominent example is that gift/flower/card companies always include this horrible printed message. Our system would allow much greater personalisation, either with your own handwriting or with the handwriting of a celebrity (who would presumably get a royalty! The world just keeps getting stranger...). It also allows us to rewrite history, as demonstrated above, so I'm sure that the Ministry of Truth will be very interested;-)
Now out of date (see above): Code will be published, but is not online yet (Well, the mean shift module is.). This is the largest, most complex system I have ever created, and its going to take months to get it all cleaned up and online. I will be presenting this paper at SIGGRAPH 2016, so am aiming to get it all done by then. We will also be releasing our dataset - that will happen much quicker, but there is little value until we have also released code to load the included files.
Regarding presenting at SIGGRAPH, that did not happen. Broke my ankle badly two weeks before, playing football (Which I don't even like!), and am still incapable of moving more than 50-100m without somewhere to rest as I write this, on the day I was meant to present. After three and a half years it's hard to think of a bigger possible let down:-(
Edit (20th August 2016): So I got a consolation prize of sorts after missing SIGGRAPH - lots of media attention. Then lots of emails, which is clearly a punishment. It took sooooo long to answer them all. Anyway, here is a list of articles about this paper:
BBC: The original article that spawned the rest, and one of the few that wasn't lazy journalism, as Rory actually came along and spent the time to talk to me, with a camera man. Timing was not the best, as the interview was the morning of the last day of 3Dami, and required preparation as Rory sent me his handwriting sample the evening before. All whilst hoping around on crutches. That was an insane day.
UCL: Obviously UCL did their own press-release thing. Very quote heavy, but accurate at least, as I got to proof read it.
A German TV show made the effort to travel to the UK and film me for a piece. Was good fun, but Google translate gives the title as "Falsifying manuscripts - crimes with artificial intelligence", so I suspect they may have portrayed me as an evil mastermind. I'm OK with that.
Digital Trends: They actually put in the effort to send me a few questions via email. It amuses me that they think my algorithm is creepy!
I got emailed some questions by the Haberturk Gazette. Can't find actual article however, as I don't know Turkish!
Reddit: So someone started a reddit discussion about it. The take home message seems to be that people want a homework machine, and this is a critical component. Someone needs to submit a grant:-P Also a concern about its use for spam mailing, which I never even considered. Worryingly, that actually seems like a serious possibility, and not something I want to be associated with. Crap.
CG Channel: This actually came before the BBC article, but given its nature nobody noticed it. Just a list of cool SIGGRAPH videos, with my handwriting paper under 'Just plain fun'. Much happier with that than 'potential spam enabler'!
Below are all articles where a journalist has read the BBC article/UCL press release and basically copied it. This is not to say they are all the same - some of them have put effort into the presentation, and its interesting to see all of the different twists/opinions they have added:
Treehugger - The use of the word 'perfectly' in the headline amuses me. If it really was perfect we would have a serious fraud problem - sometimes you actually want to fall a little short!
Gizmondo: Talk about a lazy title - those are Rory's words. To answer the question at the end about the authors own handwriting - it totally could. Your handwriting isn't actually that bad. I should know...
Engadget: OK article, author was clearly paying attention as it has a lot of details and I didn't spot any mistakes.
BT: Close examination by a magnifying glass. A normal one, that any kid can use to brutally murder ants. Not a microscope.
India TV news: Its a website. Not a TV. With a click bait headline. I am hopeful that there is going to be a point in history where the hatred of this click bait crap leads to certain words, such as wow, being banned entirely from headlines by editors.
Golem: A German one that a friend sent me. Don't speak German, though its apparently in the 'Algorithmus' section, which I think might be a gorgeous word.
The Malta Independent Online: Just a stub.
dna: An Indian stub.
Phys Org: Longish stub
I4U News: Stub.
Opp Trends: Short and wrong. They clearly tried to read the paper, and got confused somewhere, or possibly everywhere.
Cantech Letter: A stub that is apparently bought to me by eye carrot. I don't know what an eye carrot is, but it sounds painful, or at least inconvenient.
The Technews: Stub. Where do all of these stock photographs of pens on paper come from? There are just so many of them - is the market for pens on paper images really that large?
The Hindu Business Line: Another stub. Disappointed with so many foreign news websites being in English - I want all the languages!
There are more, but in the words of Miss sweetie poo, I'm bored.